Markets Are Languages, Not Physics
Why treating financial markets as natural language problems — not physics problems — yields better predictive models. The theoretical framework behind our AI trading approach, inspired by Renaissance Technologies and modern NLP.
The Wrong Metaphor
For 50 years, quantitative finance has borrowed its metaphors from physics. Brownian motion. Stochastic differential equations. Mean-field theory. The Black-Scholes equation is literally the heat equation with different boundary conditions.
This metaphor has been extraordinarily productive. It gave us options pricing, risk management, portfolio theory. But as a framework for prediction, it’s fundamentally limited — because markets are not physical systems.
Physical systems don’t read the newspaper. Particles don’t panic. Gravity doesn’t change its mind because the Fed chairman used a slightly different word in a press conference.
Markets are made of language-producing, narrative-believing, herd-following humans. And the best framework for modeling them might not be physics at all. It might be linguistics.
The Renaissance Clue
The most successful quantitative fund in history — Renaissance Technologies’ Medallion Fund — was built by mathematicians, but not finance mathematicians. Jim Simons hired cryptographers, speech recognition researchers, and computational linguists. Robert Mercer came from IBM’s speech recognition team. Peter Brown was a machine translation researcher.
This wasn’t an accident. Simons explicitly sought people who understood pattern recognition in sequential data — which is exactly what natural language processing is.
The public record suggests Renaissance treats market data as a kind of language: a sequence of symbols (price movements, volume patterns, order flow) that contains statistical regularities analogous to grammar and syntax. You don’t need to understand why a word follows another word to predict it; you need to understand the statistical structure of the sequence.
Markets as Token Sequences
Consider the analogy more precisely:
| Language | Markets |
|---|---|
| Words/tokens | Price bars, volume, order flow events |
| Grammar | Market microstructure rules |
| Sentences | Trading sessions |
| Context | Regime, macro environment |
| Semantics | Fundamental value |
| Pragmatics | Trader intent, positioning |
| Register/style | Volatility regime |
In NLP, a language model doesn’t need to “understand” meaning to generate coherent text. GPT doesn’t know what a cat is, but it can use the word correctly in context because it has learned the statistical regularities of how “cat” relates to other words.
Similarly, a market model doesn’t need to understand why prices move. It needs to learn the statistical regularities of how they move — the grammar of price action.
import numpy as np
import pandas as pd
def tokenize_price_action(
df: pd.DataFrame,
n_price_bins: int = 20,
n_volume_bins: int = 5,
n_volatility_bins: int = 5,
) -> pd.Series:
"""
Convert OHLCV data into a sequence of discrete tokens,
analogous to tokenizing text for NLP.
Each bar becomes a token encoding: direction, magnitude,
volume regime, and volatility regime.
"""
df = df.copy()
# Price change as percentage of ATR (normalized magnitude)
tr = pd.concat([
df['high'] - df['low'],
(df['high'] - df['close'].shift(1)).abs(),
(df['low'] - df['close'].shift(1)).abs()
], axis=1).max(axis=1)
atr = tr.rolling(14).mean()
change = df['close'] - df['open']
normalized_change = change / atr
# Discretize price change
price_token = pd.qcut(normalized_change, n_price_bins, labels=False, duplicates='drop')
# Discretize volume (relative to average)
rel_volume = df['volume'] / df['volume'].rolling(50).mean()
vol_token = pd.qcut(rel_volume, n_volume_bins, labels=False, duplicates='drop')
# Discretize volatility regime
vol_regime = atr / atr.rolling(100).mean()
regime_token = pd.qcut(vol_regime, n_volatility_bins, labels=False, duplicates='drop')
# Composite token: "P{price}_V{volume}_R{regime}"
tokens = (
'P' + price_token.astype(str) +
'V' + vol_token.astype(str) +
'R' + regime_token.astype(str)
)
return tokensN-gram Models: The Simplest Language Model for Markets
Before deep learning, NLP relied on n-gram models: predicting the next word based on the previous n-1 words. We can apply the same approach to market tokens:
from collections import Counter, defaultdict
class MarketNgramModel:
"""
An n-gram language model for market token sequences.
Predicts the next market state based on the previous n-1 states.
"""
def __init__(self, n: int = 5):
self.n = n
self.ngram_counts = defaultdict(Counter)
self.context_counts = defaultdict(int)
def train(self, token_sequence: list[str]):
"""Train on a sequence of market tokens."""
for i in range(len(token_sequence) - self.n):
context = tuple(token_sequence[i:i + self.n - 1])
next_token = token_sequence[i + self.n - 1]
self.ngram_counts[context][next_token] += 1
self.context_counts[context] += 1
def predict_distribution(self, context: tuple) -> dict:
"""
Given the last n-1 tokens, predict the probability distribution
of the next token.
"""
if context not in self.ngram_counts:
return {}
total = self.context_counts[context]
return {
token: count / total
for token, count in self.ngram_counts[context].items()
}
def directional_bias(self, context: tuple, neutral_token_prefix: str = 'P10') -> float:
"""
Compute directional bias: probability of bullish vs bearish next token.
Tokens with price component > neutral are bullish, < neutral are bearish.
"""
dist = self.predict_distribution(context)
if not dist:
return 0.0
bullish_prob = sum(p for t, p in dist.items() if int(t.split('V')[0][1:]) > 10)
bearish_prob = sum(p for t, p in dist.items() if int(t.split('V')[0][1:]) < 10)
return bullish_prob - bearish_prob
def perplexity(self, token_sequence: list[str]) -> float:
"""
Compute perplexity — how 'surprised' the model is by the sequence.
High perplexity = unusual market behavior = potential regime change.
"""
log_probs = []
for i in range(self.n - 1, len(token_sequence)):
context = tuple(token_sequence[i - self.n + 1:i])
token = token_sequence[i]
dist = self.predict_distribution(context)
if token in dist and dist[token] > 0:
log_probs.append(np.log2(dist[token]))
else:
log_probs.append(-10) # smoothing for unseen tokens
return 2 ** (-np.mean(log_probs)) if log_probs else float('inf')Perplexity as a Regime Change Detector
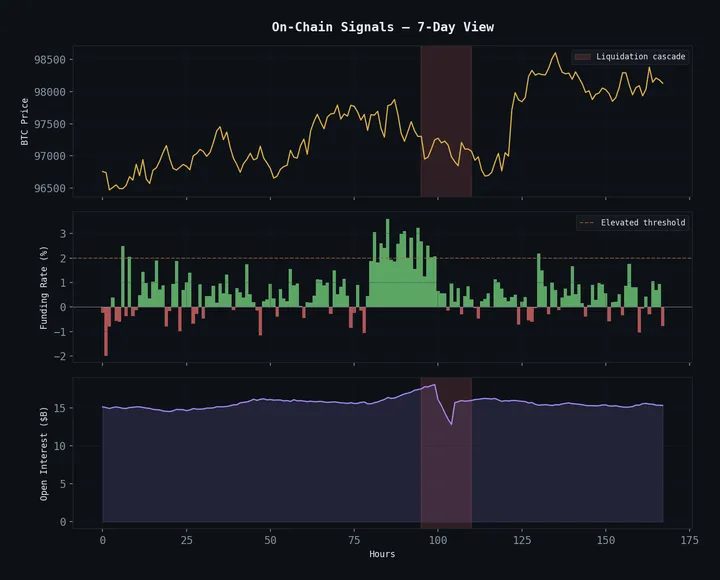
The most interesting output of the language model isn’t the prediction — it’s the perplexity. In NLP, perplexity measures how surprised the model is by a text. High perplexity means the text doesn’t follow the patterns the model learned.
Applied to markets: high perplexity means the market is behaving unlike anything the model has seen. This is a regime change indicator — and it’s completely model-agnostic. You don’t need to specify what kind of regime change you’re looking for. The perplexity spike tells you something has changed.
We track rolling perplexity and find that it spikes 4-12 bars before major volatility events with a consistency that rivals our entropy collapse signal. The two signals are related but not identical — entropy measures the information content of returns directly, while perplexity measures how unexpected the sequence of market states is.
Why LLMs Are Natural Market Models
This framework explains why LLMs are surprisingly effective at market analysis (as we demonstrate in our $1.30/day trading agent):
-
Context windows. LLMs process sequences with attention to long-range dependencies. Markets have exactly this structure — the current bar’s meaning depends on what happened 50, 100, or 500 bars ago.
-
Multi-modal reasoning. GPT-4 and Claude can process text, numbers, and structured data simultaneously. Market analysis requires synthesizing price data, news, fundamentals, and positioning data.
-
Few-shot learning. LLMs can adapt to new patterns from a few examples. Markets constantly generate new patterns that haven’t appeared in historical data.
-
Uncertainty quantification. LLMs naturally produce probability distributions over next tokens. Market prediction is inherently probabilistic — you want P(up) vs P(down), not a point forecast.
The Limits of the Metaphor
The language analogy isn’t perfect. Three important differences:
Non-stationarity. Natural language is approximately stationary — English grammar doesn’t change month to month. Market “grammar” shifts with macro regimes, regulatory changes, and participant turnover. Language models trained on 2020 market data may not generalize to 2025.
Adversarial dynamics. When enough participants learn the same patterns, those patterns can be exploited or may disappear. Language doesn’t have adversarial speakers trying to make you predict wrong. Markets do.
Reflexivity. In language, your prediction of the next word doesn’t change what the next word will be. In markets, your trade is part of the price formation process. The observer affects the observed. (George Soros built an entire philosophy around this.)
What This Means for Our Research
The language framework shapes our research priorities at Curupira:
- We prefer statistical pattern recognition over causal models. We don’t need to know why a pattern exists, just that it’s statistically robust.
- We use sequence models (n-grams, attention mechanisms) rather than point-in-time indicators. The order of market events matters.
- We monitor model perplexity as a first-class signal. When the market stops “making sense” to our models, that’s information.
- We deploy LLMs for contextual reasoning about quantitative signals, not as direct predictors. The LLM is the interpreter, not the sensor.
Markets are not physics. They’re not perfectly efficient random walks. They’re not deterministic systems waiting to be solved. They’re messy, evolving, reflexive, narrative-driven sequences produced by imperfect agents.
They’re languages. And we’re building the tools to read them.
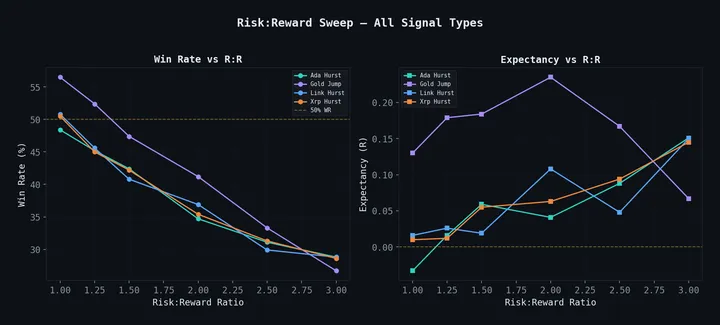
See this framework in practice: Building a $1.30/Day LLM Trading Agent applies these ideas to live trading. For the statistical foundations, start with Entropy Collapse or Hurst Exponents.